Los procesadores Intel Core i7 basados en núcleos Nehalem incorporan SMT de dos vías (Hyperthreading) en cada uno de sus cores, obteniendo así un total de ocho CPUs lógicas para cuatro núcleos físicos.

El brillo dorado de Nehalem
En sistemas operativos actuales de la familia Windows (léase XP, XP64, Vista o Vista64) no hay manera de diferenciar qué es un procesador físico y cual uno lógico. De este modo Windows, en su torpeza, asigna los threads a las CPUs lógicas sin saber realmente si son o no núcleos físicos con la consiguiente degradación de las prestaciones.
Sistema de pruebas:
- Core i7 920 @ 3.33 GHz / 2.66 GHz Uncore (Voltaje nominal)
- Turbo mode multithreaded 3.5 GHz
- Turbo mode single threaded 3.66 GHz
- BClock 167 MHz
- Placa Intel DX58SO Intel X58 - ICH10 (Voltajes nominales)
- 3 canales Kingston DDR3 1333 8-8-8-24-1T @ 1.62V
- Western Digital 500 GB WD5000AAKS 7200 rpm 16 MB SATA2
- Grabadora DVD SATA LG
- ATI Radeon 4850 512 MB GDDR3 625 MHz / 2 GHz
- F/A Tacens Radix 520W
- Instalación limpia con drivers Windows XP Home SP3

Core i7 triple channel DDR3 1333 MHz

Core i7 920. Captura de CPU-Z 1.48 en Turbo mode x22 single thread a 3666 MHz
En un sistema Core i7, en el Administrador de Tareas de Windows, encontramos ocho CPUs lógicas como podéis observar en la siguiente captura de ocho instancias de Memtest Windows:
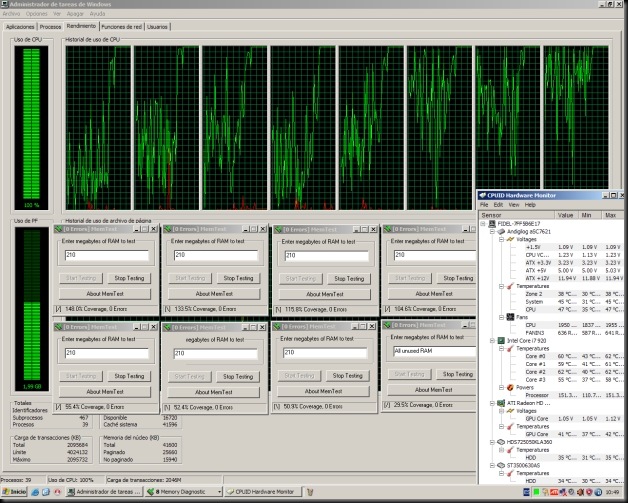
Core i7 al 100% de uso en las ocho CPUs lógicas.
Hace unos meses ya hice una evaluación similar analizando el comportamiento de los procesadores quadcore (Phenom y C2Q) en Windows y su optimización asignando manualmente cada proceso a un core.
Caso 1: Un thread - single threaded
Limitamos manualmente WinRAR para que utilice sólo la CPU lógica 0.

La velocidad obtenida en el test de WinRAR 3.80 es de 1143 KB/s utilizando solo uno de los ocho cores lógicos de Nehalem.
Caso 2: Dos threads - dual threaded
Limitamos a WinRAR a utilizar las CPUs lógicas 0 y 1:

Obtenemos una velocidad de 1908 KB/s. Estamos utilizando dos procesadores distintos.
Ahora asignamos WinRAR a las CPUs lógicas 0 y 4:

Obtenemos una velocidad inferior al caso anterior. Señal inequívoca de que la CPU lógica 0 y la 4 forman parte del mismo núcleo de procesamiento, el primer núcleo del Core i7. Pese a asignar a dos CPUs lógicas, estamos utilizando un solo procesador (con SMT).
En cambio cuando asignamos a las CPUs lógicas 0 y 1 estamos asignando a dos núcleos diferentes y de ahí el aumento de velocidad.
Caso 3: Cuatro threads - Four threaded
Asignamos manualmente WinRAR a las CPUs lógicas 0, 1, 2 y 3.
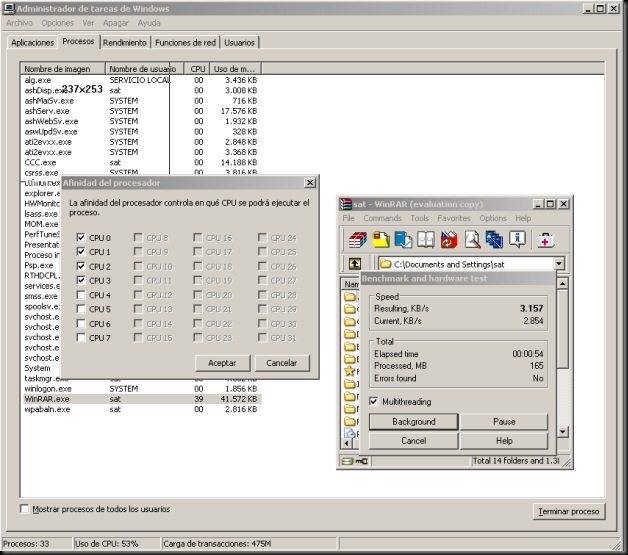
Obtenemos un índice de 3157 KB/s con cuatro CPUs lógicas que corresponden a cuatro procesadores físicos. El caso óptimo.
En cambio, si seleccionamos las CPUs lógicas 0, 1 y 4, 5 obtenemos el siguiente resultado:
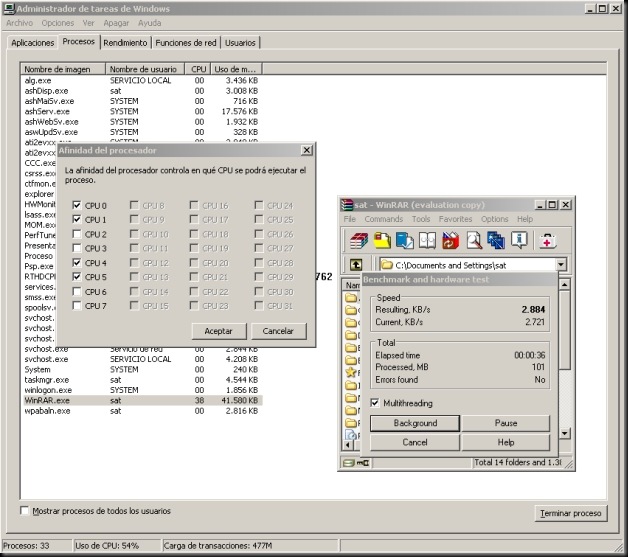
Solamente 2884 KB/s porque en este caso hemos seleccionado 4 CPUs lógicas que corresponden sólo a dos núcleos físicos con HyperThreading (SMT).
Caso 4: Ocho Threads - Eight threaded
Dejando ejecutar por defecto a WinRAR 3.80 en un sistema Core i7, obtenemos la siguiente captura:

Como decía, por defecto, queda asignado a las ocho CPUs lógicas (0, 1, 2, 3, 4, 5, 6 y 7) dando un rendimiento excepcional de casi 4200 KB/s. Recordemos que estamos en un sistema Core i7 a 3.5 GHz y Uncore a 2.66 GHz con triple canal DDR3 1333 8-8-8-24 1T.
Caso 5: Dos instancias de WinRAR - Eight threaded
Lanzando dos instancias de WinRAR y dejando todo por defecto obtenemos lo siguiente:

Ambas instancias de WinRAR están asignadas a las ocho CPUs lógicas. En este caso obtenemos 2410 y 2512 KB/s. Un total de 4930 KB/s, lo que demuestra que una sola instancia de WinRAR no es capaz de saturar un Core i7 con sus ocho threads.
Podemos también asignar cada instancia de WinRAR a cuatro CPUs lógicas para "balancear la carga" obteniendo resultados similares:

Conclusiones:
Hay que ser consciente de la complejidad de los procesadores actuales y en especial del procesador Nehalem de Intel. Al haber ocho CPUs lógicas pero sólo cuatro físicas hay que ser cuidadoso si deseamos extraer el máximo rendimiento de aplicaciones mal adaptadas a ocho threads.

KB/s en WinRAR 3.80 beta
Como vemos, la escalada de rendimiento de uno a ocho threads es ejemplar y es debida al ingente ancho de banda de esta plataforma.

Debemos saber que las CPUs lógicas 0, 1, 2 y 3 tienen sus parejas en las 4, 5, 6 y 7. Es decir la CPU lógica 0 y la 4 forman parte del mismo procesador físico y así sucesivamente.

Las ocho CPUs lógicas y los cuatro núcleos de Nehalem
Y por ello, asignando correctamente los procesos podremos extraer hasta la última gota de las prestaciones de estos excelentes procesadores.


![amd_01[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi5dxeYzoa3PJBLQ53nSyxys04UVGSc-UGoFy7CDrTmFFntvSdAPeEXSYxVBlQpNcuDCD3xsQa2qad8-ESPAfpyOUIurC2sAlCrqztW7mM2M-LOddNUFvZkXrc1Ku9JaLHYj7go5htcroo/s1600-h/amd_01%5B1%5D%5B3%5D.jpg)





























![amd_02[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiMp8SSp_gA0jjqeRplVgtFoMMJqqeuS2dmk3lTb0xlkmj2GNiJL-m-4A5ldEJOL54NY89vQMN9hpzWE7aAcfu0tUf6KLnuUBMoZfOxN5xEHAhZybd8sDoSvaniO3RbXT1rM4RQ9r3znC8/s1600-h/amd_02%5B1%5D%5B3%5D.png)


![1237333[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhUjgG3FaHR0ncUj2zLkT_e408UF8VqBdbsUYDsWyinNTjZz3d8SR9GL5MDwei6bdiniX5r5wDbKan3eSm6akaTmiFVjFhAEybxsryldLGLWxtpPH_5RIUU1fj006VOy-0TrqjPWa-9JGY/s1600-h/1237333%5B1%5D%5B3%5D.png)
![1237334[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh9U1SvKuzaHQ7U_rJeFHvCuP4pXCsBiPYgUKK4C-js-0vjUNuY6Ukt2nvszUjA6Jax4koQ2Simzye0HajX61NK6X28cXUXK1ggi7Dfk3AIAZ05PUpgKEMumSFKKMbVZGnN2GaCfzwZspk/s1600-h/1237334%5B1%5D%5B3%5D.png)
![1237344[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhHk-nMFZABZm7XE04TaY5rCw5U3C-t3k47cX-CEnXJOa7jm34Cz55UvYNce5HSGXmlhLeSOePohzc2so0_iqMT1WqwLBJSApEzPCpkHl7fvL9wbytU8miAXgOSjv53GgD39Q4ajl7dIMw/s1600-h/1237344%5B1%5D%5B3%5D.png)
![1237345[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiyfu6lbMUk28akwkxg-iubE5U34TvjbteqZ4aRf8hG_NDizi3KFefZCbXOmq6u_9CO6y2Sy8Ftdv2vLPBI-h4-MjuSt8tBG3K6erCnmSN_3KI2g-bPbYr4i-g3MFcZqHpfSB6JTUeSNvY/s1600-h/1237345%5B1%5D%5B3%5D.png)
![1237350[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjdIp4U9Xx2__jCxTd7j0jKeN0Piwrfuhj8D4NP_XpKNissQ79pSfENYZ89OZdfuX0TI8pDvGQNF97jDeFKiPqq1Tj3BzDT3UXhBcehtK2WtfDAu-H1LV9lDx3hVJ8lN4_5q9FmDXGo6cI/s1600-h/1237350%5B1%5D%5B3%5D.png)










